完成社交属性的一些功能
注意当前的配置还是集群模式,要开两个服务
一、发布探店笔记 探店笔记类似点评网站的评价,往往是图文结合。对应的表有两个:
tb_blog:探店笔记表,包含笔记中的标题、文字、图片等
tb_blog_comments:其他用户对探店笔记的评价
本节先关注第一张表,即探店笔记表,前端页面中点击首页底部的加号即可发布笔记,首先是上传图片,用了专门的请求接口,因为其他业务也需要上传图片,不仅仅是发布笔记需要,其请求为:http://localhost:8080/api/upload/blog
上传图片的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @PostMapping("blog") public Result uploadImage (@RequestParam("file") MultipartFile image) {try {String originalFilename = image.getOriginalFilename();String fileName = createNewFileName(originalFilename);new File (SystemConstants.IMAGE_UPLOAD_DIR, fileName));"文件上传成功,{}" , fileName);return Result.ok(fileName);catch (IOException e) {throw new RuntimeException ("文件上传失败" , e);private String createNewFileName (String originalFilename) {String suffix = StrUtil.subAfter(originalFilename, "." , true );String name = UUID.randomUUID().toString();int hash = name.hashCode();int d1 = hash & 0xF ;int d2 = (hash >> 4 ) & 0xF ;File dir = new File (SystemConstants.IMAGE_UPLOAD_DIR, StrUtil.format("/blogs/{}/{}" , d1, d2));if (!dir.exists()) {return StrUtil.format("/blogs/{}/{}/{}.{}" , d1, d2, name, suffix);
上传的图片不满意还可以删除图片,接口为:http://localhost:8080/api/upload/blog/delete?name=/imgs/blogs/0/15/bc97fa01-f5fb-444b-9c1a-9dca41453b0f.jpg
1 2 3 4 5 6 7 8 9 @GetMapping("/blog/delete") public Result deleteBlogImg (@RequestParam("name") String filename) {File file = new File (SystemConstants.IMAGE_UPLOAD_DIR, filename);if (file.isDirectory()) {return Result.fail("错误的文件名称" );return Result.ok();
随后是上传文字笔记的的请求和代码,点击发布,就会发出请求:http://localhost:8080/api/blog
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @RestController @RequestMapping("/blog") public class BlogController {@Resource private IBlogService blogService;@Resource private IUserService userService;@PostMapping public Result saveBlog (@RequestBody Blog blog) {UserDTO user = UserHolder.getUser();return Result.ok(blog.getId());
发布完笔记会跳转到个人主页,也可以去首页往下拖查看,因为暂时没有人点赞,所以排在最下面。暂时无法查看笔记,因为还没实现。
接下来实现查看发布探店笔记详情页面的接口:http://localhost:8080/api/blog/7
与网站首页根据点赞数排序分页查询笔记列表的接口:http://localhost:8080/api/blog/hot?current=1
这里有个注意点是,我们期望显示笔记内容的同时也显示用户的姓名、头像等信息,这些属性在表tb_blog里是没有的,所以我们需要在实体类里面添加这些属性,然后加上注解@TableField(exist = false)。
controller层
1 2 3 4 5 6 7 8 9 10 @GetMapping("/{id}") public Result queryBlogById (@PathVariable("id") Long id) {return blogService.queryBlogById(id);@GetMapping("/hot") public Result queryHotBlog (@RequestParam(value = "current", defaultValue = "1") Integer current) {return blogService.queryHotBlog(current);
service层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Service public class BlogServiceImpl extends ServiceImpl <BlogMapper, Blog> implements IBlogService {@Resource private IUserService userService;@Override public Result queryHotBlog (Integer current) {"liked" )new Page <>(current, SystemConstants.MAX_PAGE_SIZE));this .queryBlogUser(blog);return Result.ok(records);@Override public Result queryBlogById (Long id) {Blog blog = getById(id);if (blog == null ) {return Result.fail("笔记不存在!" );return Result.ok(blog);private void queryBlogUser (Blog blog) {Long userId = blog.getUserId();User user = userService.getById(userId);
这样就完成了初步的首页笔记列表和笔记详情的查询功能,其中点赞部分功能后续实现
二、点赞 需求:
同一个用户只能点赞一次,再次点击则取消点赞
如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
实现步骤:
①给Blog类中添加一个isLike字段,标示是否被当前用户点赞
②修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
③修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段
④修改分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
controller层
1 2 3 4 @PutMapping("/like/{id}") public Result likeBlog (@PathVariable("id") Long id) {return blogService.likeBlog(id);
service层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public Result likeBlog (Long id) {Long userId = UserHolder.getUser().getId();String key = BLOG_LIKED_KEY + id;Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());if (BooleanUtil.isFalse(isMember)) {boolean isSuccess = update().setSql("liked = liked + 1" ).eq("id" , id).update();if (isSuccess) {else {boolean isSuccess = update().setSql("liked = liked - 1" ).eq("id" , id).update();if (isSuccess) {return Result.ok();
修改两个查询blog的业务,将点赞的查询也加入进去,具体查询方法和上面类似,代码省略
随后可以去进行测试,点赞并取消赞,观察DB和redis的变化
三、点赞排行榜 在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜。
这里其实就是把上一节redis的set换成zset,时间作为score,只是用来熟悉 Sortedset 这个数据结构,毕竟还要保证点赞用户的唯一性,不能使用列表来排序
不过利用 range 从 zset 里取出来的东西如何解析为用户数据,也是个难点
然后就是有个问题,数据库里用select in() 的时候,括号里的顺序,需要自己手动指定
这个业务在真正的大众点评中是有的,但是个人感觉几乎没啥用处,好像没有人会去关注最先点赞的人是谁,是哪几个,无所谓的(或者可能是看有没有刷点赞?)感觉不太影响面试,暂时先不记录了
四、好友关注 1. 关注与取关
在别人的笔记页面有一个关注按钮,我们可以对其进行关注和取关,这涉及到两个请求接口:
一个是关注或取关:
另一个是查询是否关注了该用户:
关注是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来标示:
1 2 3 4 5 6 7 8 create table tb_followbigint auto_increment comment '主键' primary key,bigint unsigned not null comment '用户id' ,bigint unsigned not null comment '关联的用户id' ,timestamp default CURRENT_TIMESTAMP not null comment '创建时间'
controller层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @RestController @RequestMapping("/follow") public class FollowController {@Resource private IFollowService followService;@PutMapping("/{id}/{isFollow}") public Result follow (@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {return followService.follow(followUserId, isFollow);@GetMapping("/or/not/{id}") public Result isFollow (@PathVariable("id") Long followUserId) {return followService.isFollow(followUserId);
service层,由于后面要实现共同关注,使用redis的set集合取交集功能,所以存入DB的同时也存入redis
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Override public Result follow (Long followUserId, Boolean isFollow) {Long userId = UserHolder.getUser().getId();String key = "follows:" + userId;if (isFollow) {Follow follow = new Follow ();boolean isSuccess = save(follow);if (isSuccess) {else {boolean isSuccess = remove(new QueryWrapper <Follow>()"user_id" , userId).eq("follow_user_id" , followUserId));if (isSuccess) {return Result.ok();@Override public Result isFollow (Long followUserId) {Long userId = UserHolder.getUser().getId();Integer count = query().eq("user_id" , userId).eq("follow_user_id" , followUserId).count();return Result.ok(count > 0 );
随后可以测试关注和取关功能
2. 共同关注 共同关注功能:表现层
1 2 3 4 @GetMapping("/common/{id}") public Result followCommons (@PathVariable("id") Long id) {return followService.followCommons(id);
业务层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public Result followCommons (Long id) {Long userId = UserHolder.getUser().getId();String key = "follows:" + userId;String key2 = "follows:" + id;if (intersect == null || intersect.isEmpty()) {return Result.ok(Collections.emptyList());return Result.ok(users);
随后可以测试共同关注功能,可以去别人个人主页依赖两个接口在补充的资料里补充完整即可
3. 滚动分页关注推送 关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
传统的模式是用户主动去搜索内容信息,而 Feed 模式是内容自动匹配用户,主动推送给用户
Feed流产品有两种常见模式:
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:拉模式、推模式、推拉结合。具体区别可以看视频,我们的项目比较简单,使用推模式即可
基于推模式实现关注推送功能:
需求 :
①修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
②收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override public Result saveBlog (Blog blog) {UserDTO user = UserHolder.getUser();boolean isSuccess = save(blog);if (!isSuccess){return Result.fail("新增笔记失败!" );"follow_user_id" , user.getId()).list();for (Follow follow : follows) {Long userId = follow.getUserId();String key = FEED_KEY + userId;return Result.ok(blog.getId());
③查询收件箱数据时,可以实现分页查询
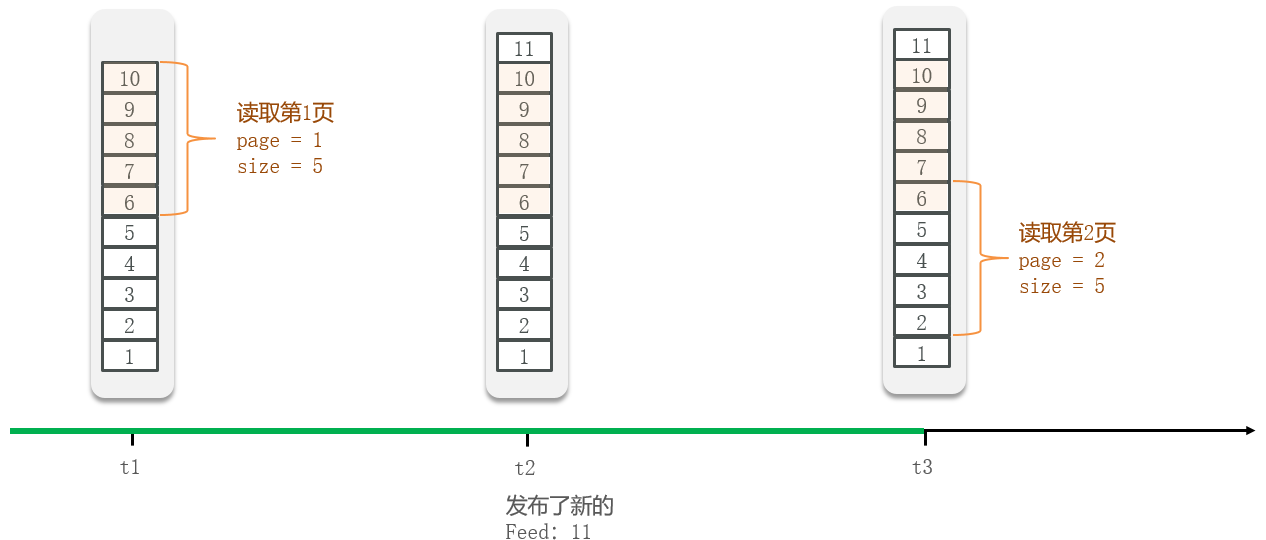
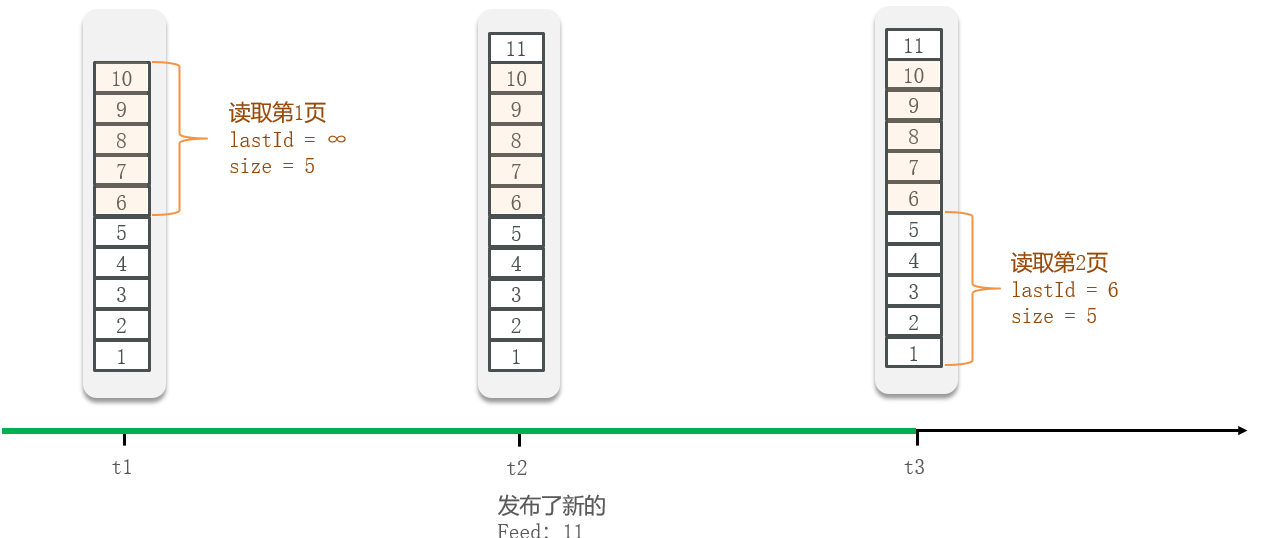
Feed流的分页问题:Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
我们可以记录上次读取的最后一条记录,然后在此记录之后查询新的分页
滚动查询的实现还是有些难度的,忘记了多看几遍视频,主要是使用redis sortedset结构,其 zrange 命令是按照角标查询,就是传统的分页模式,而滚动分页模式则应该使用 zrangebyscore limit 命令,即按照分数排序查询,并且要记住上次查询结构的最后一个分数(对应到项目场景其实就是时间戳)。该命令需要四个参数:
max:上一次查询到的最小时间戳(第一次查询)或当前时间戳(第二次及以后的查询)
min :0,时间没有负数,这个是固定的
offset(偏移量):0(第一次查询没有偏移量)或 与上次查询最小时间戳一致的所有元素的个数 (第二次及以后的查询,避免时间戳相同带来问题,具体的看视频)
count :每页多少条数据,这个也是固定的,这里设置为3
这些对应到请求命令里,请求路径是: /blog/of/follow
请求参数是:
lastId: 上一次查询的最小时间戳
offset: 偏移量 其他参数是固定的
返回值:
List:小于指定时间戳的笔记集合
minTime:本次查询的推送的最小时间戳,传给下次查询
offset:偏移量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @Override public Result queryBlogOfFollow (Long max, Integer offset) {Long userId = UserHolder.getUser().getId();String key = FEED_KEY + userId;0 , max, offset, 3 );if (typedTuples == null || typedTuples.isEmpty()) {return Result.ok();new ArrayList <>(typedTuples.size());long minTime = 0 ; int os = 1 ; for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { long time = tuple.getScore().longValue();if (time == minTime){else {1 ;String idStr = StrUtil.join("," , ids);"id" , ids).last("ORDER BY FIELD(id," + idStr + ")" ).list();for (Blog blog : blogs) {ScrollResult r = new ScrollResult ();return Result.ok(r);
随后可以进行测试
五、附近商户 GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
GEOADD :添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
GEODIST :计算指定的两个点之间的距离并返回
GEOHASH :将指定member的坐标转为hash字符串形式并返回
GEOPOS :返回指定member的坐标
GEORADIUS :指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃
GEOSEARCH :在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
GEOSEARCHSTORE :与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
功能暂时不实现了
六、用户签到 签到功能用DB实现过于冗余,
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0,把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。
BitMap的操作命令有:
SETBIT :向指定位置(offset)存入一个0或1
GETBIT :获取指定位置(offset)的bit值
BITCOUNT :统计BitMap中值为1的bit位的数量
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
功能暂时不实现了
七、UV统计 首先我们搞懂两个概念:
UV:全称 Unique visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
PV:全称 Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。可以实现唯一性,即不包括重复用户
HyperLogLog的作用:做海量数据的统计工作
HyperLogLog的优点:内存占用极低,性能非常好
HyperLogLog的缺点:有一定的误差